

Artificial intelligence (AI) continues to redefine the boundaries of technology across multiple industries, from software development and cybersecurity to finance and design. The recent introduction of Claude Sonnet 4.5 by Anthropic marks a substantial advancement in AI's ability to solve complex problems, not only in coding but also in broad reasoning, real-world computer use, and extended multi-step tasks. This in-depth analysis explores what makes Claude Sonnet 4.5 a game-changer, the innovations it brings, reactions from stakeholders, its safety and alignment improvements, and its broader context in the evolving landscape of AI tools.
The Claude Sonnet 4.5 Breakthrough
What is Claude Sonnet 4.5?
Claude Sonnet 4.5 is Anthropic's latest AI model, touted as the world's best coding model and leading the way in complex agent design and computer usage. Available immediately on Anthropic's platforms and API, it comes at no additional cost compared to its predecessor, Sonnet 4. According to Anthropic, this upgrade includes significant enhancements in reasoning, mathematics, alignment, and software tool use, positioning it at the frontier of AI innovation.
Key Product Upgrades
Alongside the model release, Anthropic introduced improvements such as:
- Claude Code Checkpoints: New functionality allowing users to save progress, instantly roll back, and boost troubleshooting efficiency.
- Native VS Code Extension: Seamless integration for developers to work within familiar environments.
- Context Editing and API Memory Tool: Enables longer runs for agents and manages greater task complexity and continuity.
- In-app Code Execution and File Creation: Users can now run code and generate documents, slides, or spreadsheets directly within conversation threads.
- Chrome Extension Expansion: The upgraded Claude for Chrome tool is now accessible to 'Max' users, further integrating Claude's capabilities into daily workflows.
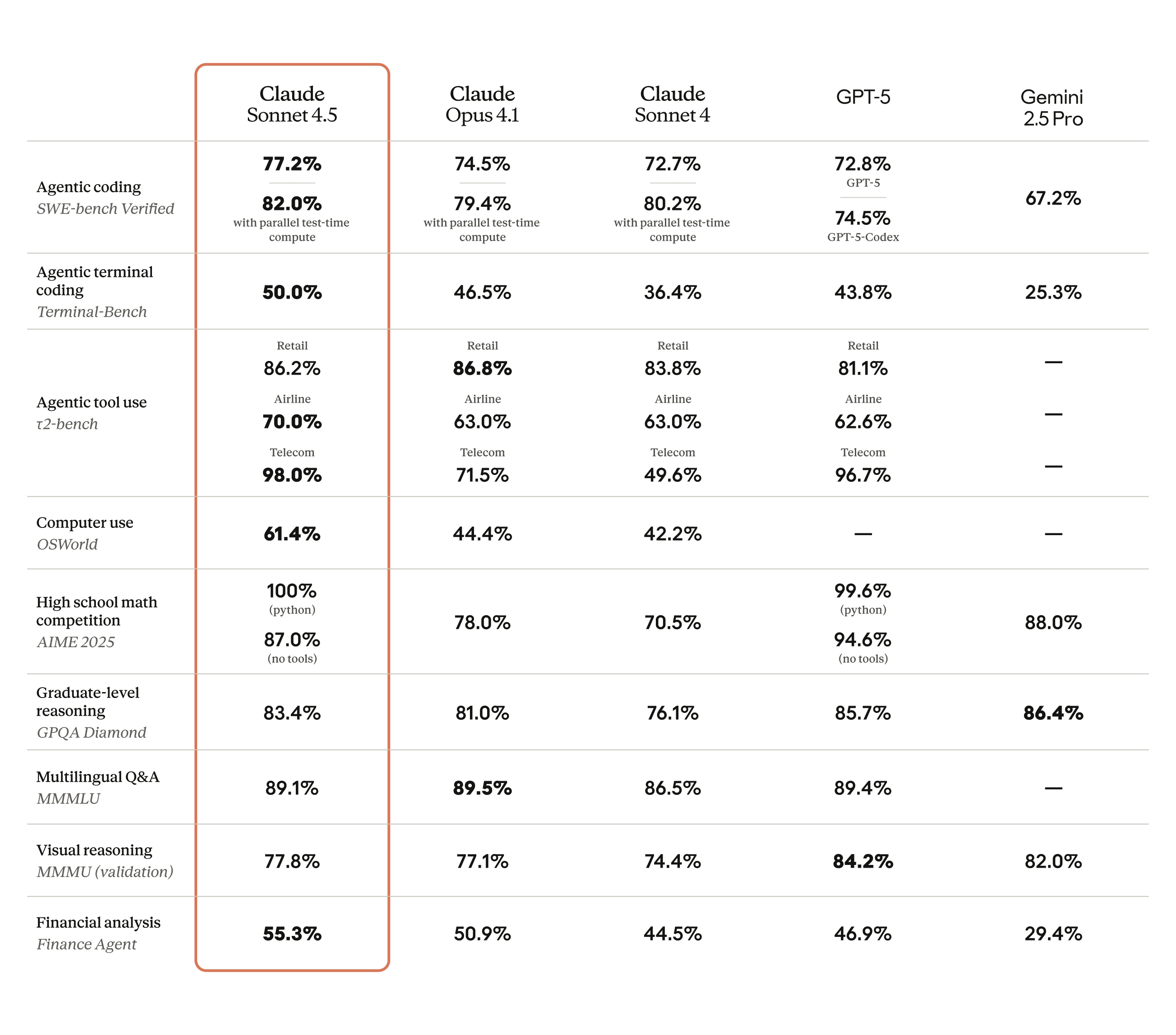
In-Depth Performance Analysis
Benchmarking and Real-World Use
Sonnet 4.5 excels on major industry evaluation platforms:
- SWE-bench Verified: Achieves leading results in real-world software coding challenges, maintaining focus over 30+ hours on long, complex assignments.
- OSWorld: Commands a 61.4% success rate, an impressive jump from the previous model at 42.2% just months before.
- Domain Mastery: Specialists in finance, law, medicine, and STEM disciplines report "dramatic" strides in domain-specific reasoning over earlier Claude versions and rivals such as Opus 4.1.
Customer Experiences and Case Studies
Organizations report tangible improvements in workflow and output:
- Software Development: Claude Sonnet 4.5 boosts accuracy, speeds up long-horizon tasks, learns codebase patterns, and captures architectural intent for faster feature delivery.
- Cybersecurity: Security teams using Hai agents saw a 44% reduction in vulnerability intake time and a 25% improvement in accuracy.
- Legal Analysis: Assistance in synthesizing legal opinions and thorough examination of litigation records.
- Design and Productivity: Platforms like Canva and Figma note improvements in prototyping, functional interaction, and productivity across engineering teams.
Efficiency and Multi-Tasking
A distinctive feature of Sonnet 4.5 is its parallel execution ability—running multiple bash commands at once for greater productivity. For AI-powered agents such as Devin, Sonnet 4.5's planning and evaluation saw the most marked improvements since model 3.6, especially in autonomous, long-context coding operations.
Multiple Perspectives
Developers and Engineers
For software engineers and developers, Sonnet 4.5 isn't just about raw coding speed. Users highlight its deep contextual awareness, ability to edit and debug at scale, and enhanced support for knowledge-intensive tasks that require both analytical rigor and creative problem-solving.
Security and Finance Professionals
Security teams benefit from the AI's ability to rapidly triage vulnerabilities and generate creative attack scenarios, strengthening defenses for critical infrastructure. Financial analysts observe that the model delivers investment-grade insights, optimizing risk screenings and asset evaluations with reduced human review.
Design and Productivity Stakeholders
Designers and product managers value the model's contributions to prototyping, functional testing, and the creative process. Fast iteration and more intelligent interaction help teams transform ideas into polished, viable products with fewer bottlenecks.
Users of Prompt Libraries and AI Productivity Tools
In tandem with Claude’s upgrade are platforms like AISuperHub, which aggregate high-quality prompts for AI models including Claude, ChatGPT, and Gemini, helping users get the most out of powerful AI functionalities for coding, analysis, content creation, and more.[^2][^3]
Supporting Evidence: Quantitative Metrics
Anthropic reports Sonnet 4.5’s strength using quantitative benchmarks:
| Benchmark | Sonnet 4.5 Score | Previous Best (Sonnet 4) | Highlights |
|---|---|---|---|
| SWE-bench Verified | 77.2% | Lower | Coding, real-world problems, 30+ hr focus |
| OSWorld | 61.4% | 42.2% (Sonnet 4) | Real-world computer tasks |
| Internal Code Editing | 0% error rate | 9% (previous model) | Dramatic reduction in code editing errors |
| Vulnerability Intake | 44% faster | Baseline | For Hai security agents |
| Accuracy Improvement | +25% | Baseline | In vulnerability intake tasks |
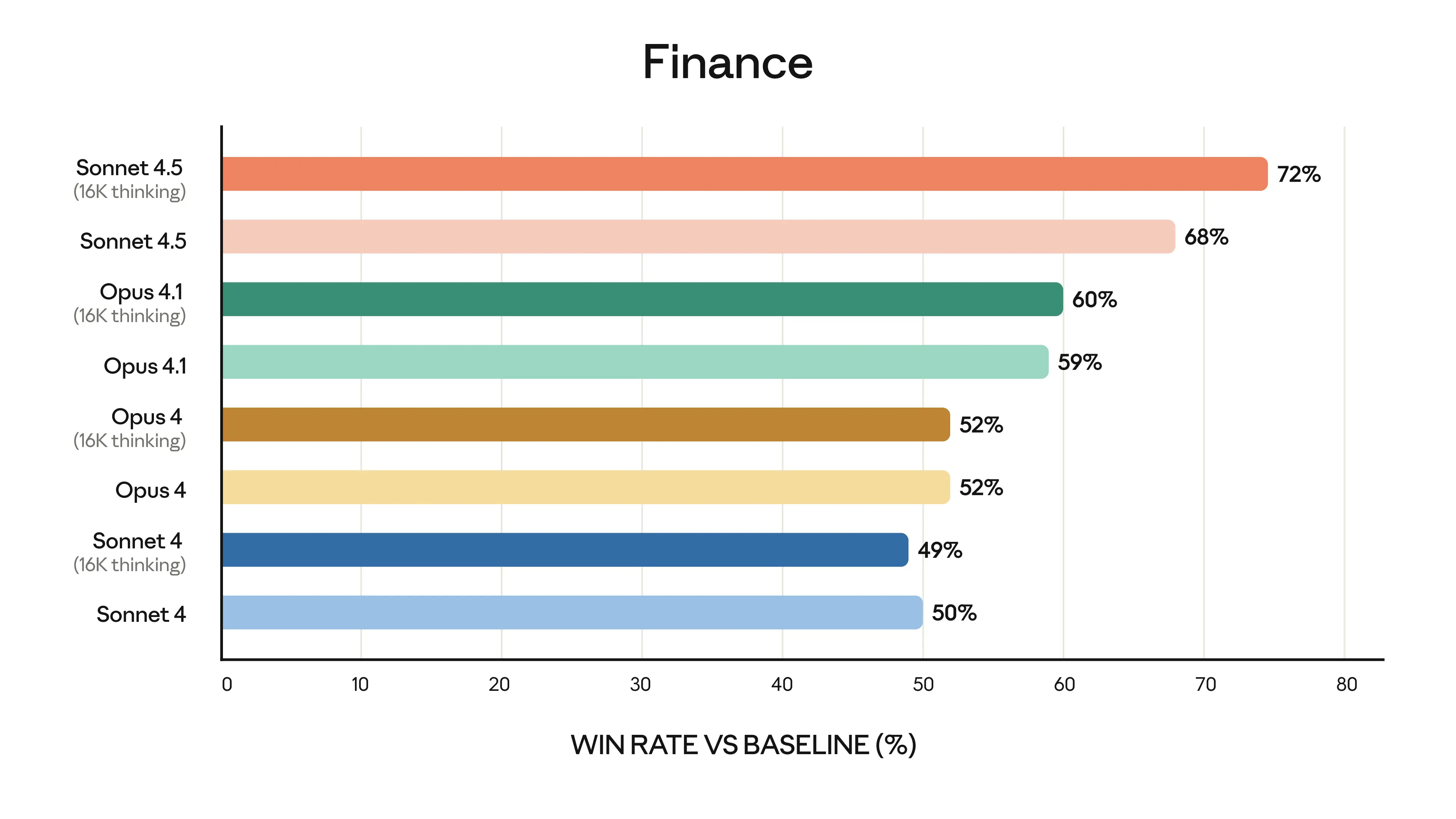
Contextual Background
The Evolution of AI Coding Models
The past two years have witnessed a rapid evolution in AI models for coding and multi-domain problem-solving. OpenAI, Google (Gemini), and Anthropic have engaged in a competitive race to capture both technical and practical leadership. Each new generation expands the context window, improves reasoning and memory, and better manages complex processes like agent design or autonomous system development.[^4][^5]
Prompt Engineering and Productivity Hubs
Resources like AISuperHub enable users to leverage thousands of expert-crafted prompts, optimizing the productivity and accuracy of AI outputs. These "prompt hubs" help both professionals and enthusiasts harness the full power of AI tools, effectively bridging the gap between raw model power and everyday utility.
Safety, Alignment, and Security
Advances in Model Alignment
Anthropic emphasizes Sonnet 4.5’s alignment and safety features. The new model reduces concerning behaviors—sycophancy, deception, and power-seeking—while defending against prompt injection attacks, which are critical for agentic and autonomous tasks. New classifier-based filters target dangerous content scenarios, especially relating to high-risk domains such as CBRN (chemical, biological, radiological, nuclear) risks, lowering false positives drastically since earlier model iterations.
Mechanistic Interpretability and Safety Levels
For the first time, Sonnet 4.5’s safety validation incorporates techniques from mechanistic interpretability, deepening transparency in how and why the model behaves as it does. Anthropic deploys the model under its AI Safety Level 3 (ASL-3), matching the increased power to stronger safeguards and controls. Users in high-stakes domains can opt for allowlist participation and direct collaboration with Anthropic’s support and research teams.
Expanded Tooling: The Claude Agent SDK
A key development accompanying Sonnet 4.5 is the public release of the Claude Agent SDK—previously internal infrastructure for Anthropic’s own agentic tools. The SDK empowers developers to build AI agents capable of managing long tasks, handling nuanced permissions, and orchestrating multiple subagents toward shared outcomes. Developers now have access to the same tools that power frontier AI applications, expanding what’s possible in automation and custom solution development.
Creativity Preview: 'Imagine with Claude'
Anthropic's forward-looking research includes "Imagine with Claude," a limited-time preview where Claude Sonnet 4.5 generates software in real time, adapting instantly to user requests and demonstrating the dynamic creativity achievable with cutting-edge models. This research initiative not only showcases the model’s capability but also signals where the next generation of AI-human collaboration could be headed.
Forward-Looking Insights
Potential Implications
- Software Engineering: Teams may shift how they design, debug, and deploy code, with AI agents increasingly central to both routine and complex processes.
- Cybersecurity: Shorter vulnerability lifecycles may become the norm, but continuous vigilance over prompt and model safety is required.
- Knowledge Work: As AI tackles longer, multi-step challenges, it might push knowledge workers into even more strategic, creative, and supervisory roles, while delegating technical drudgery to models like Sonnet 4.5.
- Prompt Economy: As platforms like AISuperHub demonstrate, prompt engineering could transform into a vital skillset for maximizing AI effectiveness, blending creativity, technical expertise, and domain knowledge.
Conclusion
Claude Sonnet 4.5 stands at the forefront of AI innovation, raising standards in code generation, reasoning, and multi-domain support. Its blend of technical power, alignment, safety features, and tooling for agentic applications positions it not just as a new benchmark for AI development, but as a harbinger of the next era in intelligent systems. Stakeholders across technology, security, finance, and design are already reaping the benefits, while resources like prompt libraries expand access and utility even further. As AI models grow in capability and responsibility, thoughtful deployment, rigorous safety safeguards, and collaborative tool development will be essential in realizing their full promise for society.
Disclaimer: The opinions expressed in this blog post are for informational purposes only and do not constitute professional advice. Readers should consult with qualified professionals for specific guidance regarding technology adoption or AI deployment decisions.*


